大數據技術原理與應用 第九章 數據處理技術的核心開發實踐
隨著大數據技術體系的不斷演進,數據處理技術作為從原始數據中提取價值的關鍵環節,其開發實踐日益受到關注。本章聚焦于大數據處理技術的核心開發原理與應用,旨在為技術開發者提供一套從理論到實踐的清晰路徑。
數據處理技術開發的核心在于構建高效、可靠且可擴展的數據處理流水線。這通常涵蓋數據采集、存儲、計算、分析與服務等多個層面。在技術選型上,開發者需要根據業務場景的具體需求,在批處理與流處理之間做出權衡。例如,對于需要高吞吐、離線分析的歷史數據,Apache Hadoop的MapReduce或Apache Spark的批處理引擎是經典選擇;而對于要求低延遲、實時響應的場景,Apache Flink、Apache Storm或Spark Streaming等流處理框架則更為合適。
在開發實踐中,有幾個關鍵技術點需要重點關注:
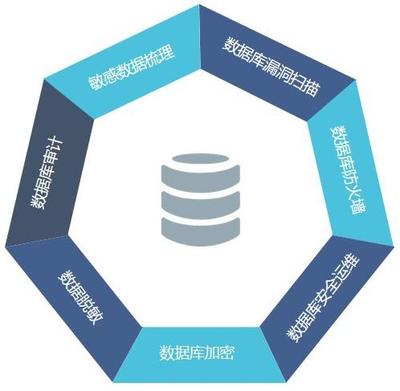
數據質量與一致性是基石。開發中必須設計有效的數據清洗、去重、校驗與修復機制。利用如Apache NiFi、Kafka Connect等工具可以實現可靠的數據攝取,并結合Schema Registry管理數據格式,從源頭保障質量。
計算模型的抽象與優化至關重要。無論是MapReduce的“分而治之”,還是Spark基于內存的DAG(有向無環圖)執行模型,理解其底層原理有助于編寫更高效的代碼。開發者應熟練運用分區(Partitioning)、廣播變量(Broadcasting)、緩存(Caching)等技術來優化性能,并關注數據傾斜等常見問題的解決方案。
狀態管理與容錯性是流處理開發中的難點與重點。像Flink提供的精確一次(Exactly-once)語義狀態管理,允許開發者在應用故障時恢復狀態,確保計算結果的準確性。這要求開發者在設計應用時,明確狀態后端的選擇和檢查點(Checkpoint)機制的配置。
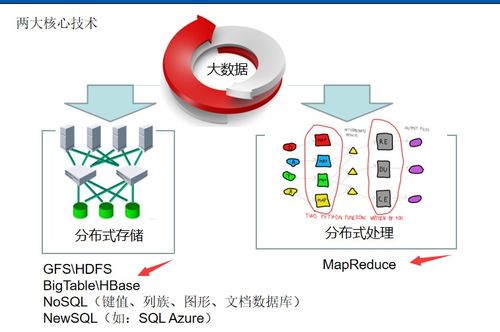
與存儲系統的深度集成是提升效率的關鍵。數據處理框架需要與HDFS、HBase、Kafka、各類云存儲及數據湖(如Delta Lake、Iceberg)無縫協作。開發者應理解不同存儲系統的特性(如列存、索引、事務支持),以便在讀寫數據時做出最佳設計。
可觀測性與運維是生產級開發不可忽視的一環。集成監控指標(如吞吐量、延遲)、日志聚合與告警系統,并利用Kubernetes等平臺實現容器化部署與彈性伸縮,能極大地提升系統的可維護性。
數據處理技術開發正朝著更智能化、一體化和云原生的方向發展。機器學習與數據處理的融合(如Spark MLlib)、流批一體架構的普及(如Flink的統一API),以及Serverless數據處理服務的興起,都在不斷降低開發門檻并提升效率。開發者需持續學習,掌握核心原理,并靈活運用工具,方能構建出穩健而強大的大數據處理系統,真正釋放海量數據的潛在價值。
如若轉載,請注明出處:http://www.51-network.cn/product/78.html
更新時間:2026-06-06 04:40:08